Notes
APMA 1650 - Spring 2020
Multivariate Distributions
Learning Goals
- Know what a joint distribution of a two or more random variables is (continuous or discrete).
- Know how to compute probabilities, as well as marginals and conditional distributions of joint distributions.
- Understand what it means for two random variables to be independent and how to test it.
Introduction
In real life, you will most often be interested in data that has multiple values of interest in an experiment. In probabilistic language, this means you are interested in the outcome of two or more random variables at the same time. The goal of this is often to deduce some kind of relationship (or lack thereof) between the data (this can be measured using the notions of covariance and correlation which we will discuss in the next lecture).
For example, you might be interested in:
- Number of Coronavirus deaths and the average age of a population
- The number of posts per day and the number of followers of Instagram users
- The frequency of exercise and the academic performance of college students
- The salary and gender of a population in a country
Question
How do you expect that the two variables in the above examples are related? Can you think of any other pairs of random variables that you might be interested in?
Another situation where we are often interested in multiple random variables is when conducting repeated experiments that have some variability. In this case (assuming the experiment is done correctly) the outcomes of each experiment should be independent in that the outcome of one experiment shouldn't affect the outcome of the next (we will discuss in more detail what it means for two random variables to be independent in later on in these notes). In fact we have been dealing with multiple independent random variables already in the setting of the law of large numbers and the central limit theorem (something that we will comeback to later).
Joint Distributions
When dealing with multiple random variables, say $X, Y$ it is important to understand how they are they are distributed together. Since it is possible that $X$ can depend on $Y$, the statistics of $(X,Y)$ can reveal behavior that simply studying the statistics of $X$ or $Y$ alone cannot.
Discrete Case
Lets start with the case when the random variables are discrete. We first introduce the idea of a joint probability distribution which describes how both $X$ and $Y$ are distributed.
Since $X$ and $Y$ are discrete (and can therefore only take on a finite or countable number of values), the joint distribution $p(x,y)$ is only non-zero at a countable number of values.
Note
Knowing the distributions of $X$ and $Y$ separately is generally not enough to determine the joint distribution of $X$ and $Y$ (unless they are independent as we will see later). As we will see, the joint distribution $p(x,y)$ contains information about how the random variables $X$ and $Y$ depend on one another.
Suppose that $X$ takes values $\{x_1,x_2,\ldots,x_n\}$ and $Y$ takes values $\{y_1,y_2,\ldots y_m\}$. Then the pair $(X,Y)$ takes values $\{(x_1,y_1),(x_2,y_2), \ldots (x_n,y_m)\}$. The joint distribution $p(x_i,y_j)$ can be organized into a joint probability table.
| $ X \backslash Y$ | $y_1$ | $y_2$ | $\ldots$ | $y_m$ |
|---|---|---|---|---|
| $x_1$ | $p(x_1,y_1)$ | $p(x_1,y_2)$ | $\ldots$ | $p(x_1,y_m)$ |
| $x_2$ | $p(x_2,y_1)$ | $p(x_2,y_2)$ | $\ldots$ | $p(x_2,y_m)$ |
| $\vdots$ | $\ldots$ | $\ldots$ | $\ldots$ | $\ldots$ |
| $x_n$ | $p(x_n,y_1)$ | $p(x_n,y_2)$ | $\ldots$ | $p(x_n,y_m)$ |
Joint probability distributions must satisfy the following properties
- $0\leq p(x,y) \leq 1$ for all $x,y$.
- All the probabilities add up to one \[ \sum_{x}\sum_{y} p(x,y) = 1, \] where the sum is over all values $x,y$ such that $p(x,y) \neq 0$.
Note: The above summation is over a discrete set of values since $X$ and $Y$ are discrete. It can be an infinite sum.
Lets consider some examples:
Example 1 (Roll two fair dice)
Recall from the notes on discrete probability the problem of rolling two fair dice. Let
then the probability table is given by:
| $X\backslash Y$ | 1 | 2 | 3 | 4 | 5 | 6 |
|---|---|---|---|---|---|---|
| 1 | $\frac{1}{36}$ | $\frac{1}{36}$ | $\frac{1}{36}$ | $\frac{1}{36}$ | $\frac{1}{36}$ | $\frac{1}{36}$ |
| 2 | $\frac{1}{36}$ | $\frac{1}{36}$ | $\frac{1}{36}$ | $\frac{1}{36}$ | $\frac{1}{36}$ | $\frac{1}{36}$ |
| 3 | $\frac{1}{36}$ | $\frac{1}{36}$ | $\frac{1}{36}$ | $\frac{1}{36}$ | $\frac{1}{36}$ | $\frac{1}{36}$ |
| 4 | $\frac{1}{36}$ | $\frac{1}{36}$ | $\frac{1}{36}$ | $\frac{1}{36}$ | $\frac{1}{36}$ | $\frac{1}{36}$ |
| 5 | $\frac{1}{36}$ | $\frac{1}{36}$ | $\frac{1}{36}$ | $\frac{1}{36}$ | $\frac{1}{36}$ | $\frac{1}{36}$ |
| 6 | $\frac{1}{36}$ | $\frac{1}{36}$ | $\frac{1}{36}$ | $\frac{1}{36}$ | $\frac{1}{36}$ | $\frac{1}{36}$ |
Since there are $36$ cells in the table, the total probability clearly sums up to one.
This table is pretty boring since it does not indicate an interesting relationship between the random variables $X$, and $Y$. In fact $X$ and $Y$ are independent.
As a more interesting case, consider another random variable \[ Z = 7-X, \] which takes what ever $X$ gives and "flips" it around 3. Then $X$ and $Z$ are clearly dependent, since the value of $X$ completely determines the value of $Z$, the probability table becomes:
| $X\backslash Z$ | 1 | 2 | 3 | 4 | 5 | 6 |
|---|---|---|---|---|---|---|
| 1 | 0 | 0 | 0 | 0 | 0 | 1/6 |
| 2 | 0 | 0 | 0 | 0 | 1/6 | 0 |
| 3 | 0 | 0 | 0 | 1/6 | 0 | 0 |
| 4 | 0 | 0 | 1/6 | 0 | 0 | 0 |
| 5 | 0 | 1/6 | 0 | 0 | 0 | 0 |
| 6 | 1/6 | 0 | 0 | 0 | 0 | 0 |
If you were to look at the distribution of just $Z$, you wouldn't be able to tell that $Z$ was "copying" off of $X$. This can only be recognized by considering the joint distribution.
We can also consider more complicated events.
Example 2
Let $X$ and $Y$ be as in the previous example. What is the probability that $X < Y$?
The event $\{X < Y\}$ can be described explicitly as the set of $(x,y)$ pairs
This can be visualized as a triangular subset of the probability table considered in Example 1, colored salmon below:
| $X\backslash Y$ | 1 | 2 | 3 | 4 | 5 | 6 |
|---|---|---|---|---|---|---|
| 1 | $\frac{1}{36}$ | $\frac{1}{36}$ | $\frac{1}{36}$ | $\frac{1}{36}$ | $\frac{1}{36}$ | $\frac{1}{36}$ |
| 2 | $\frac{1}{36}$ | $\frac{1}{36}$ | $\frac{1}{36}$ | $\frac{1}{36}$ | $\frac{1}{36}$ | $\frac{1}{36}$ |
| 3 | $\frac{1}{36}$ | $\frac{1}{36}$ | $\frac{1}{36}$ | $\frac{1}{36}$ | $\frac{1}{36}$ | $\frac{1}{36}$ |
| 4 | $\frac{1}{36}$ | $\frac{1}{36}$ | $\frac{1}{36}$ | $\frac{1}{36}$ | $\frac{1}{36}$ | $\frac{1}{36}$ |
| 5 | $\frac{1}{36}$ | $\frac{1}{36}$ | $\frac{1}{36}$ | $\frac{1}{36}$ | $\frac{1}{36}$ | $\frac{1}{36}$ |
| 6 | $\frac{1}{36}$ | $\frac{1}{36}$ | $\frac{1}{36}$ | $\frac{1}{36}$ | $\frac{1}{36}$ | $\frac{1}{36}$ |
Since there are $15$ such elements, we see that \[ P(X< Y) = \frac{15}{36}. \]
The concept of joint probability can easily be generalized to the case of $n$ random variables
Let $X_1, X_2, \ldots X_n$ be discrete random variables, then the joint probability distribution of $X_1,X_2,\ldots X_n $ is given by
Of course we must still, have $0\leq p(x_1,x_2,\ldots,x_n)\leq 1$, and \[ \sum_{x_1,x_2,\ldots,x_n} p(x_1,x_2,\ldots, x_n) = 1 \] where the sum is over all values of $(x_1,x_2,\ldots x_n)$ such that $p(x_1,x_2,\ldots, x_n)\neq 0$.
Continuous Case
To treat two continuous random variables, $X$ and $Y$. We start by analogy with the single variable case. Namely instead of evaluating probabilities at specific values, we must evaluate probabilities on subsets of $\mathbb{R}^2$. In this case, we can think of the probability distribution as being given by the the infinitesimal probability associated to some joint probability density $f(x,y)$ (or joint pdf)
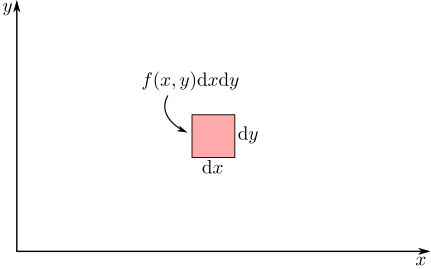
In general we can describe probabilities for $X$ and $Y$ using multivariable calculus and area integrals.
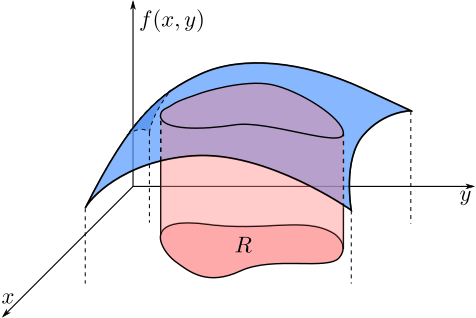
The integral in \eqref{eq:area-int} is an area integral and can be approximated by a sum \[ \iint_R f(x,y)\mathrm{d}A \approx \sum_{ij} f(x_i,y_j) \Delta x_i \Delta y_j \] of volumes of rectangular prisms each with volume $f(x_i,y_j)\Delta x_i \Delta y_j$. We can interpret $p(i,j) = f(x_i,y_j)\Delta x_i \Delta y_j$ as a joint probability distribution function associated to the rectangle centered around $(x_i,y_j)$.
Just as with the single variable case, a joint probability density must satisfy non-negativity and normality.
A joint probability density $f(x,y)$ for two continuous random variables $X$ and $Y$ must satisfy
- $0\leq f(x,y)$ for all $x,y \in \mathbb{R}$.
- The total integral is 1, \[ \int_0^\infty\int_0^\infty f(x,y)\mathrm{d}x\mathrm{d}y = 1. \]
Computing Double Integrals (a review)
The area integral in the definition \eqref{eq:area-int}, can be calculated by iterated integrals if $R$ can be cleanly described in certain coordinates.
Rectangular coordinates:If $R$ is the rectangle $R = [a,b]\times[c,d]$, then we have
Depending, on $f(x,y)$, the integral can then be computed by first freezing $x$, integrating $y$ and then integrating $x$ (or vice-versa). See the iterated integral section of Paul's Online Notes for a refresher on how to do this as well as some examples.
Regions bounded by functions: If $R$ is a more general region bounded between two curves $g_1(x)\leq g_2(x)$ so that
Polar coordinates: As another example if the region $R$ is a circle $R = \{x^2 + y^2 \leq 1\}$, then the area integral can be written as an iterated polar integral
Example 3
Suppose that $X$ and $Y$ are continuous random variables with values in $[0,1]$ and joint density given by \[ f(x,y) = \begin{cases} cxy , & \text{if } 0\leq x,y\leq 1\\ 0 & \text{otherwise}\end{cases} \]
What is the value of $c$ that makes this a valid joint pdf? For this value of $c$, what is the probability that $X>1/2$ and $Y<1/2$?
Clearly $f(x,y) \geq 0$, if $c \geq 0$, and therefore we simply need to check the normality condition 2. We can do this using iterated partial integrals:
Therefore we need $c = 4$ for this to be a valid joint pdf.
To find the probability that $X>1/2$ and $Y<1/2$ we note that
Lets consider a more complicated joint density defined over a different shaped region.
Example 4 (Triangular Region)
This problem is taken from Example 5.4 in the text.
Suppose that $Y_1$ and $Y_2$ are continuous random variables with values in $[0,1]$ such that $Y_2\leq Y_1$ and the joint density given by \[ f(x,y) = \begin{cases} cy_1 , & \text{if } 0\leq y_2\leq y_1\leq 1\\ 0 & \text{otherwise}\end{cases} \]
What is the value $c$ that makes $f(y_1,y_2)$ a valid joint density function? What is the probability that $0\leq Y_1 \leq 1/2$ and $Y_2 > 1/4$?
Let's check the normality condition. First, we should recognize that the domain of $f(y_1,y_2)$ is a triangular region (shown in the figure below)
This is a region bounded between two curves and there integral can be set up as
Therefore we must have $c=3$.
To compute the probability that $0\leq Y_1 \leq 1/2$ and $Y_2 > 1/4$ we need to carefully consider the region we are integrating over. Note, for instance, that if $Y_1 < 1/4$, then since $Y_2 \leq Y_1$, it's not possible for $Y_2 \geq 1/4$. We need to consider how the region $\{0\leq y_1\leq 1/2,y_2 > 1/4\}$ overlaps with the triangular domain $ D = \{0\leq y_2\leq y_1 \leq 1\}$. This is illustrated in the following figure.
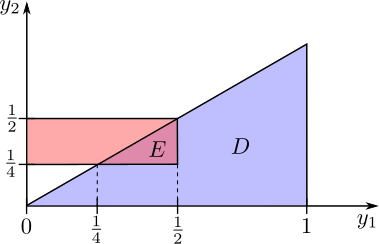
The associated integral is
Of course this can all be extended in a straight-forward way to the case of $n$ jointly distributed random variables. However, this is beyond the scope of this course.
Let $X_1, X_2, \ldots X_n$ be continuous random variables, then the joint pdf, $f(x_1,x_2,\ldots,x_n)$, of $X_1,X_2,\ldots X_n $ is define in terms of the $n$-dimensional volume integral
where $R\subset \mathbb{R}^n$ is any subregion of $n$ dimensional space. In this setting, it is useful to think of \[ \mathbf{X} = (X_1,X_2,\ldots,X_n) \] as a random $n$-dimensional vector in.
Joint Cumulative Distribution
As was the case with single random variables, the distribution of probability between two discrete or continuous random variables can be characterized by the joint cumulative distribution function (or joint cdf)
This can be written in terms of the joint distribution of joint density in the discrete or continuous cases.
If $X$ and $Y$ are discrete random variables with joint distribution function $p(x,y)$, then the joint cdf is just given by
\[ F(x,y) = \sum_{u\leq x}\sum_{v \leq y} p(u,v), \]where the sum is over $u$ and $v$ such that $p(u,v) \neq 0$.
Example 5
Let $X$ and $Y$ be as in the previous example be as in example 1. What is $F(3.5,4)$?
$F(3.5,4)$ is just the event $X\leq 3.5, Y\leq 4$, we can visualize this shading cells in the probability table, colored salmon below:
| $X\backslash Y$ | 1 | 2 | 3 | 4 | 5 | 6 |
|---|---|---|---|---|---|---|
| 1 | $\frac{1}{36}$ | $\frac{1}{36}$ | $\frac{1}{36}$ | $\frac{1}{36}$ | $\frac{1}{36}$ | $\frac{1}{36}$ |
| 2 | $\frac{1}{36}$ | $\frac{1}{36}$ | $\frac{1}{36}$ | $\frac{1}{36}$ | $\frac{1}{36}$ | $\frac{1}{36}$ |
| 3 | $\frac{1}{36}$ | $\frac{1}{36}$ | $\frac{1}{36}$ | $\frac{1}{36}$ | $\frac{1}{36}$ | $\frac{1}{36}$ |
| 4 | $\frac{1}{36}$ | $\frac{1}{36}$ | $\frac{1}{36}$ | $\frac{1}{36}$ | $\frac{1}{36}$ | $\frac{1}{36}$ |
| 5 | $\frac{1}{36}$ | $\frac{1}{36}$ | $\frac{1}{36}$ | $\frac{1}{36}$ | $\frac{1}{36}$ | $\frac{1}{36}$ |
| 6 | $\frac{1}{36}$ | $\frac{1}{36}$ | $\frac{1}{36}$ | $\frac{1}{36}$ | $\frac{1}{36}$ | $\frac{1}{36}$ |
Since there are $12$ such elements, we see that \[ F(3.5,4) = \frac{12}{36}. \]
If $X$ and $Y$ are continuous random variables with joint pdf $f(x,y)$, then the joint cdf is just given by
\[ F(x,y) = \int_{-\infty}^x\int_{-\infty}^y f(u,v)\,\mathrm{d}v\mathrm{d}u. \]We can also recover the joint pdf from the joint cdf using partial derivatives \[ f(x,y) = \frac{\partial^2 F}{\partial x \partial y}(x,y). \]
Example 6
Let $Y_1$ and $Y_2$ be as in Example 4. What is the joint cdf?
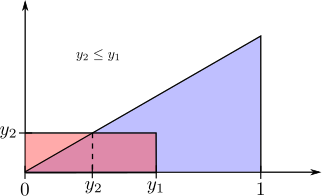
The event $Y_1 \leq y_1$ and $Y_2\leq y_2$ depends on whether $y_1 \leq y_2$ or $y_1 \geq y_2$. Both cases are illustrated below
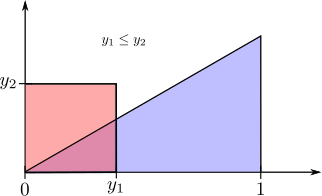
If $0\leq y_1 \leq y_2\leq 1$, then the region of integration is a triangle
On the other hand, if $0\leq y_2 \leq y_1\leq 1$ then the region of integration can be split up into a triangle and rectangle
Putting this together gives
As was the case in one dimension, the joint cdf has various properties
If $X$ and $Y$ are any random variables with joint cdf $F(x,y)$ then the following properies hold
- F(x,y) is non-decreasing, meaning that if $x$ or $y$ increase, then $F(x,y)$ can't decrease
- If you send any variable to $-\infty$, then $F(x,y)$ goes to zero, i.e. $F(-\infty,-\infty) = F(-\infty,y) = F(x,-\infty) =0.$
- If you send both variables to $+\infty$, then $F(x,y)$ approaches $1$, i.e. $F(\infty,\infty ) = 1$.
Using the cdf to calculate probabilities of rectangles
Just like in the single variable case, the cdf can be used to calculate probabilities on rectangles. This can be stated more precisely as: if $x_1 \geq x_2$ and $y_1 \geq y_2$, then the following rule holds.
This is illustrated in the following animation using the additive and subtractive properties of probability. Positive contributions are colored red and negative contributions are colored blue.
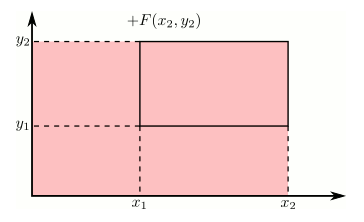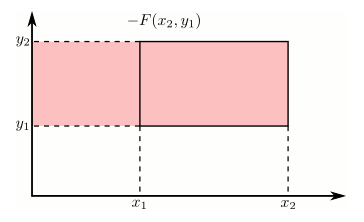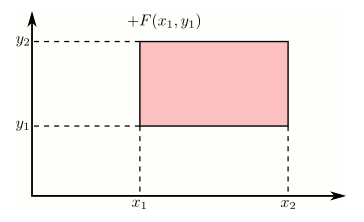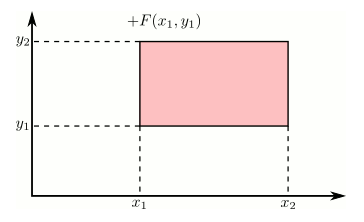
Marginal distributions
If two random variables $X$ and $Y$ are jointly distributed, it is often the case that you want to understand the distribution just one of them, ignoring any relationship between the two of them, such a distribution is called a marginal distribution.
Discrete case
Lets begin by considering an example:
Example 7
Recall the die tossing experiment from Example 1. Suppose we consider the event $\{X = 3\}$. We know that this corresponds to the the following pairs
| $X\backslash Y$ | 1 | 2 | 3 | 4 | 5 | 6 |
|---|---|---|---|---|---|---|
| 1 | $\frac{1}{36}$ | $\frac{1}{36}$ | $\frac{1}{36}$ | $\frac{1}{36}$ | $\frac{1}{36}$ | $\frac{1}{36}$ |
| 2 | $\frac{1}{36}$ | $\frac{1}{36}$ | $\frac{1}{36}$ | $\frac{1}{36}$ | $\frac{1}{36}$ | $\frac{1}{36}$ |
| 3 | $\frac{1}{36}$ | $\frac{1}{36}$ | $\frac{1}{36}$ | $\frac{1}{36}$ | $\frac{1}{36}$ | $\frac{1}{36}$ |
| 4 | $\frac{1}{36}$ | $\frac{1}{36}$ | $\frac{1}{36}$ | $\frac{1}{36}$ | $\frac{1}{36}$ | $\frac{1}{36}$ |
| 5 | $\frac{1}{36}$ | $\frac{1}{36}$ | $\frac{1}{36}$ | $\frac{1}{36}$ | $\frac{1}{36}$ | $\frac{1}{36}$ |
| 6 | $\frac{1}{36}$ | $\frac{1}{36}$ | $\frac{1}{36}$ | $\frac{1}{36}$ | $\frac{1}{36}$ | $\frac{1}{36}$ |
Using the additive law of probability, we can calculate $P(X=3)$ by summing along the rows of the table
Of course we already knew this!
Motivated by the example, we define marginal distributions
Suppose that $X$ and $Y$ are discrete random variables with joint distribution function $p(x,y)$. The marginal distribution functions $p_X(x)$ and $p_Y(y)$ for $X$ and $Y$ respectively are given by summing the joint distribution over the other variable
The marginals can be visualized in the following extension of the joint probability table, where the sums of each row and column are located on the right and bottom margins.
| $ X \backslash Y$ | $y_1$ | $y_2$ | $\ldots$ | $y_m$ | $p_X(x)$ |
|---|---|---|---|---|---|
| $x_1$ | $p(x_1,y_1)$ | $p(x_1,y_2)$ | $\ldots$ | $p(x_1,y_m)$ | $p_X(x_1)$ |
| $x_2$ | $p(x_2,y_1)$ | $p(x_2,y_2)$ | $\ldots$ | $p(x_2,y_m)$ | $p_X(x_2)$ |
| $\vdots$ | $\ldots$ | $\ldots$ | $\ldots$ | $\ldots$ | $\vdots$ |
| $x_n$ | $p(x_n,y_1)$ | $p(x_n,y_2)$ | $\ldots$ | $p(x_n,y_m)$ | $p_X(x_n)$ |
| $p_Y(y)$ | $p_Y(y_1)$ | $p_Y(y_2)$ | $\ldots$ | $p_Y(y_m)$ | $1$ |
Note
The marginal distributions say very little about a joint distribution. Two random variables can have the same marginal distribution and be very dependent on one another. For instance if $X$ is the outcome of a fair die roll, then $Z= 7- X$ has the same marginal distribution as $X$ even though $Z$ is completely determined by the outcome of $X$.
Continuous Case
The continuous case is similar to the discrete case, where sums are replaces with integrals.
Suppose that $X$ and $Y$ are continuous random variables with joint pdf $f(x,y)$. The marginal distribution pdfs $f_X(x)$ and $f_Y(y)$ for $X$ and $Y$ respectively are given by integrating out the other variable.
Example 8
Consider the joint pdf from Example 3
Find the $X$ and $Y$ marginals.
To find $f_X(x)$ we integrate out the $y$ variable and to find $f_Y(y)$ we integrate out the $x$ variable.
Example 9
Consider the more complicated pdf of Example 4
Find the $X$ and $Y$ marginals.
Taking into account the triangular region,
Marginal cdf
Finding the marginal cdf from a given joint cdf is actually pretty easy. No integration or summation is necessary.
Let $X$ and $Y$ be two random variables with joint cdf $F(x,y)$, then the marginal cdfs are given by
Note that if $X$ and $Y$ only take values in a rectangle $[a,b]\times [c,d]$, then this can be simplified to evaluating $x$ or $y$ at the right end point of it's respective domain,
Lets illustrate this ideas with a more complicated example.
Example 10
Lets consider the cdf we calculated from Example 6.
Find the $X$ and $Y$ marginal cdfs.
Evaluating at the $y_1 = 1$ and $y_2 = 1$ gives
Note that $F^\prime_{Y_1}(y_1) = 3y_1^2$ and $F^\prime_{Y_2}(y_2) = \frac{3}{2}(1-y_2^2)$, which is consistent with the answers to Example 9.
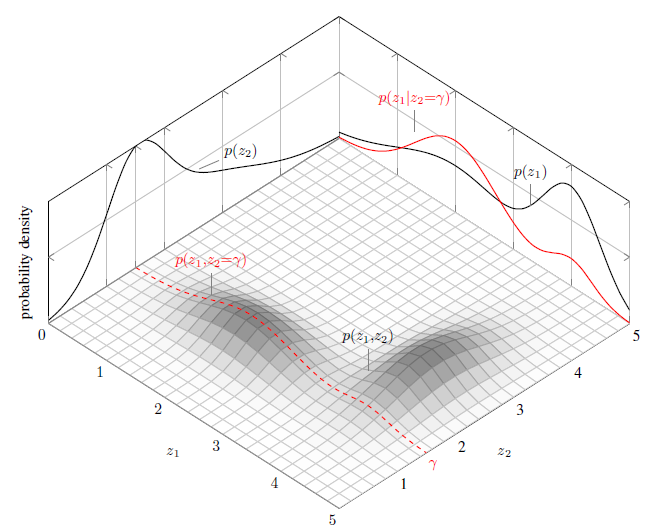
Conditional Distributions
In addition to marginal distributions, one can also define conditional distributions that describe the distribution of one random variable given the value of another.
Discrete case
Recall the definition of conditional probability of $A$ given $B$.
We can apply this formula to the distribution of two discrete random variables $X$ and $Y$, using the random variables to define events like $\{X = 1\}$ and $\{Y= 2\}$. Then we can consider the probability $X$ taking a certain value given that $Y$ takes a different value by
This motivates the following definition.
Let $X$ and $Y$ be two random variables with joint distribution $p(x,y)$, then the conditional distribution function of $X$ given $Y$ is
Note
$p(x|y)$ is undefined if $p_Y(y) = 0$. This is because it doesn't make sense to condition on a probability zero event.
Continuous case
The continuous case is much more subtle. For instance, it is hard to define \[ P(X\leq x|Y=y), \] since the probability that $\{Y=y\}$ is zero.
However, one of the remarkable features of continuous probability distributions is that it is possible to make sense of conditioning on $\{Y=y\}$ by taking a limit. For instance, we can define a conditional cdf by shrinking the interval $[y,y+h]$ to the point $y$ and defining
The next result shows that this limit exists and
Let $X$ and $Y$ be two continuous random variables with joint pdf $f(x,y)$ and joint cdf $F(x,y)$, then the conditional cdf of $X$ given $Y$ is defined by
Proof:
The expression $P(X\leq x| y \leq Y \leq y+h)$ is well defined since $P(y \leq Y \leq y+h) \neq 0$ for some values of $y$.
We can calculate this limit explicitly since
where in the last line we multiplied and divided by $\frac{1}{h}$. Using the fact that
as $h\to 0$, completes the proof.
QED
This motivates the following definition of the conditional pdf by taking the derivative of the conditional cdf.
Let $X$ and $Y$ be two continuous random variables with joint pdf $f(x,y)$, then the conditional pdf of $X$ given $Y$ is
Example 11
Lets consider pdf from Example 6.
Find $f(y_1|y_2)$ and use it to calculate $P(Y_1\leq 3/4|Y_2 = 1/2)$.
From example 9, we found that \[ f_{Y_2}(y_2) = \frac{3}{2}(1-y_2^2) \quad 0\leq y_2\leq 1. \] Therefore
To calculate $P(Y_1\leq 1/2|Y_2 = 1/2)$ we note that
Therefore
Independence of Random Variables
We can now give a precise definition of independence of two random variables.
Recall that two events $A$ and $B$ are independent if and only if \[ P(A\cap B) = P(A)P(B). \] Of course we can take $A$ and $B$ to be events defined to two random variables $X$ and $Y$, for instance $A = \{X \leq 3\}$ and $B= \{Y\geq 1\}$. We then say that two random variables $X$ and $Y$ are independent if any event defined by $X$ and any event defined by $Y$ are independent. As it turns out it's good enough to consider events of the form $\{X\leq x\}$ and $\{Y\leq y\}$ for all $x$ and $y$, the condition \[ P(X \leq x, Y\leq y) = P(X\leq x)P(Y\leq y) \] guarantees independence.
Two random variables $X$ and $Y$ with joint cdf $F(x,y)$ and marginal cdfs $F_X(x)$ and $F_Y(y)$ are independent if and only if
Otherwise $X$ and $Y$ are said to be dependent.
In the discrete case, the definition can be reduced to:
Two discrete random variables $X$ and $Y$ with joint distribution function $p(x,y)$ and marginal distributions $p_X(x)$ and $p_Y(y)$ are independent if and only if
Otherwise $X$ and $Y$ are said to be dependent.
In the discrete case, independence means the probability in a cell of the probability table must be the product of the marginal probabilities of its row and column. This is considered in the next example.
Example 12
Lets consider the die rolling experiment from Example 1. Of course we know that $X$ and $Y$ are independent, but lets check that out notion of independence is correct.
The probability table is
| $X\backslash Y$ | 1 | 2 | 3 | 4 | 5 | 6 | $p_X(x)$ |
|---|---|---|---|---|---|---|---|
| 1 | $\frac{1}{36}$ | $\frac{1}{36}$ | $\frac{1}{36}$ | $\frac{1}{36}$ | $\frac{1}{36}$ | $\frac{1}{36}$ | $\frac{1}{6}$ |
| 2 | $\frac{1}{36}$ | $\frac{1}{36}$ | $\frac{1}{36}$ | $\frac{1}{36}$ | $\frac{1}{36}$ | $\frac{1}{36}$ | $\frac{1}{6}$ |
| 3 | $\frac{1}{36}$ | $\frac{1}{36}$ | $\frac{1}{36}$ | $\frac{1}{36}$ | $\frac{1}{36}$ | $\frac{1}{36}$ | $\frac{1}{6}$ |
| 4 | $\frac{1}{36}$ | $\frac{1}{36}$ | $\frac{1}{36}$ | $\frac{1}{36}$ | $\frac{1}{36}$ | $\frac{1}{36}$ | $\frac{1}{6}$ |
| 5 | $\frac{1}{36}$ | $\frac{1}{36}$ | $\frac{1}{36}$ | $\frac{1}{36}$ | $\frac{1}{36}$ | $\frac{1}{36}$ | $\frac{1}{6}$ |
| 6 | $\frac{1}{36}$ | $\frac{1}{36}$ | $\frac{1}{36}$ | $\frac{1}{36}$ | $\frac{1}{36}$ | $\frac{1}{36}$ | $\frac{1}{6}$ |
| $p_Y(y)$ | $\frac{1}{6}$ | $\frac{1}{6}$ | $\frac{1}{6}$ | $\frac{1}{6}$ | $\frac{1}{6}$ | $\frac{1}{6}$ | 1 |
Since each marginal has probability $\frac{1}{6}$ and each cell has probability $\frac{1}{36}$ (the produce of the marginals), we can see that $X$ and $Y$ are independent.
On the otherhand, lets consider $X$ and $Z = 7 -X$. The probability table was given by
| $X\backslash Z$ | 1 | 2 | 3 | 4 | 5 | 6 | $p_X(x)$ |
|---|---|---|---|---|---|---|---|
| 1 | 0 | 0 | 0 | 0 | 0 | $\frac{1}{6}$ | $\frac{1}{6}$ |
| 2 | 0 | 0 | 0 | 0 | $\frac{1}{6}$ | 0 | $\frac{1}{6}$ |
| 3 | 0 | 0 | 0 | $\frac{1}{6}$ | 0 | 0 | $\frac{1}{6}$ |
| 4 | 0 | 0 | $\frac{1}{6}$ | 0 | 0 | 0 | $\frac{1}{6}$ |
| 5 | 0 | $\frac{1}{6}$ | 0 | 0 | 0 | 0 | $\frac{1}{6}$ |
| 6 | $\frac{1}{6}$ | 0 | 0 | 0 | 0 | 0 | $\frac{1}{6}$ |
| $p_Z(z)$ | $\frac{1}{6}$ | $\frac{1}{6}$ | $\frac{1}{6}$ | $\frac{1}{6}$ | $\frac{1}{6}$ | $\frac{1}{6}$ | 1 |
In this table, we can see that many of the probabilities are not the product of two marginal probabilities and so $X$ and $Z$ are dependent. Indeed, since none of the marginal probabilities are zero, then none of the cells with zero probability can be a product of marginals.
In the continuous case (by taking partial derivatives), this can be reduced to a statement on the pdfs:
Two continuous random variables $X$ and $Y$ with joint pdf $f(x,y)$ and marginal pdfs $f_X(x)$ and $f_Y(y)$ are independent if and only if
Otherwise $X$ and $Y$ are said to be dependent.
In many ways the continuous case is easier to check that the discrete case, since it can be reduced to showing that the density can be factored into a product of two densities.
Example 13
Let $X$ and $Y$ have joint density \[ f(x,y) = \begin{cases} 4xy & \text{if}\quad 0\leq x ,y\leq 1\\ 0 & \text{otherwise}\end{cases} \] Are $X$ and $Y$ independent?In this case, since $f_X(x) = 2x$ for $0\leq x \leq 1$ and $f_Y(y) = 2y$ and $0\leq y\leq 1$, we can easily see that for $0\leq x,y\leq 1$, \[ f_X(x)f_Y(y) = 4xy = f(x,y). \]
Example 14
How about the pdf from Example 6? Are $Y_1$ and $Y_2$ independent?
In this case, we know that for $0\leq y_1\leq 1$ and $0\leq y_2 \leq 1$ we have
So that for all $0\leq y_1,y_2\leq 1$
This is no where close to $f(y_1,y_2)$ if not for the simple fact that $f_{Y_1}(y_1)f_{Y_2}(y_2) \neq 0$ when $0\leq y_1\leq y_2 \leq 1$ while $f(y_1,y_2) = 0$.
 - Sam Punshon-Smith 2020
- Sam Punshon-Smith 2020